
💡How Large Language Models Work? A Simple Guide with Figures and 3D Visuals
LLM Architecture, Attention Mechanism, Parameters, Training Time

Large Language Models (LLMs) like GPT-4, Claude, and Gemini have revolutionized artificial intelligence, demonstrating remarkable capabilities in text generation, reasoning, and problem-solving. But how do these sophisticated systems actually work? This comprehensive guide explores the architecture, components, and training processes that make LLMs possible. You can see the 3D LLM model link in below section.
Understanding Large Language Models
Large Language Models (LLMs) are neural networks trained on vast amounts of text data to predict the next word in a sequence. At their core, they learn statistical patterns in language, enabling them to generate coherent, contextually relevant text. The "large" in LLM refers both to their massive parameter counts (billions to trillions of parameters) and the enormous datasets they're trained on.
The breakthrough that enabled modern LLMs came with the introduction of the transformer architecture in 2017 (https://arxiv.org/pdf/1706.03762), which solved key limitations of previous approaches and became the foundation for virtually all state-of-the-art language models
The Transformer Architecture
The transformer architecture, introduced in the paper "Attention Is All You Need," revolutionized natural language processing by replacing recurrent neural networks (RNNs) with a mechanism called self-attention. This innovation allows models to process entire sequences simultaneously rather than word by word, dramatically improving both training efficiency and model performance.
Attention Is All You Need Paper: https://arxiv.org/abs/1706.03762
Key Components of Transformers
Transformers consist of two main components:
Encoder: Processes the input sequence and creates rich representations of each token in context. The encoder is used in models like BERT that focus on understanding text.
Decoder: Generates output sequences one token at a time, using both the encoder's representations and previously generated tokens. GPT-style models use only the decoder portion.
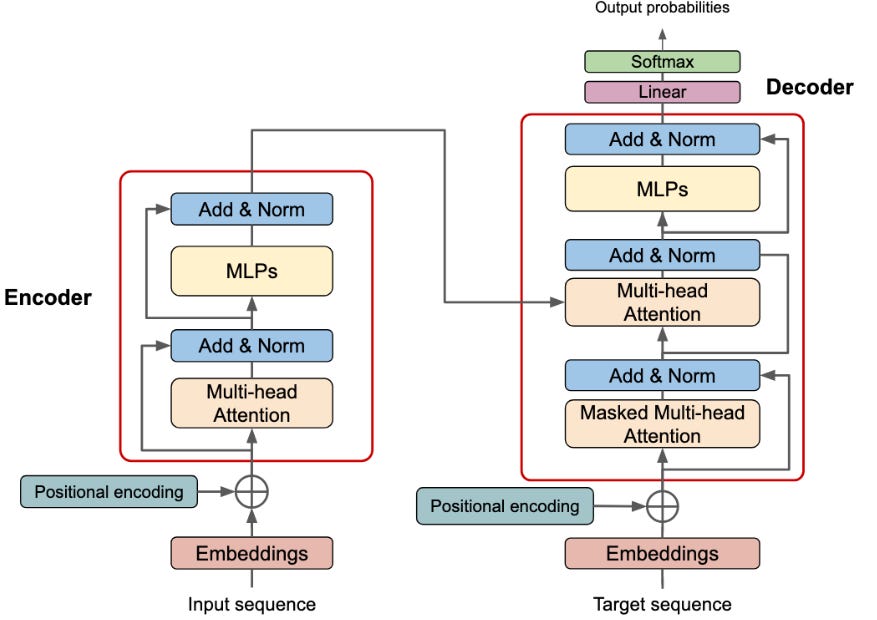
Transformer (Encoder, Decoder) from Re-cinq

Image above shows the transformer architecture, left side is encoder, right side is decoder.
Most modern LLMs like GPT use a decoder-only architecture, which has proven highly effective for text generation tasks. It means that only right side of the image above, decoder part is using in LLMs.
Embeddings: Converting Words to Numbers
What Are Embeddings?
Embeddings are dense numerical representations of words, tokens, or other discrete elements that capture semantic meaning. Unlike one-hot encoding (where each word is represented by a sparse vector with a single 1), embeddings are dense vectors typically containing hundreds or thousands of dimensions.
How Embeddings Work
When text enters an LLM, it's first tokenized (broken into smaller units like words or subwords), then each token is converted to an embedding vector. These vectors are learned during training and position semantically similar words close together in the embedding space.
For example, the words "king," "queen," "man," and "women" would have embedding vectors that are relatively close to each other in the high-dimensional space, while "king" and "bicycle" would be far apart.
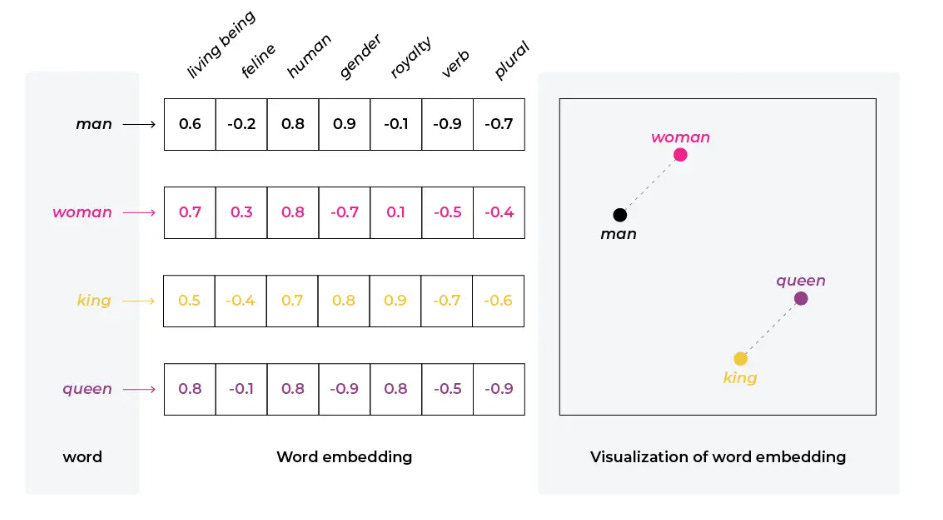
Embedding Vectors in Practice
In a typical LLM:
Each token in the vocabulary gets a unique embedding vector
These vectors are typically 512 to 4096 dimensions
The embedding matrix is one of the first learned parameters
Similar tokens cluster together in the embedding space
The Attention Mechanism
Attention is the core innovation that makes transformers so powerful. It allows the model to focus on relevant parts of the input sequence when processing each token, similar to how humans pay attention to specific words when reading.
How Attention Works
The attention mechanism works by:
Query, Key, Value: Each token creates three vectors - a query (what I'm looking for), a key (what I represent), and a value (what information I contain)
Similarity Calculation: The model calculates how similar each token's query is to every other token's key
Weighted Combination: Based on these similarities, the model creates a weighted combination of all tokens' values
Context Integration: This allows each token to incorporate information from all other relevant tokens in the sequence
Mathematical Foundation
The attention mechanism can be expressed as:

Where Q, K, and V are the query, key, and value matrices, and d_k is the dimension of the key vectors.
Multi-Head Attention
Why Multi-Head Attention?
Single attention mechanisms can only capture one type of relationship at a time. Multi-head attention runs multiple attention mechanisms in parallel, allowing the model to attend to different types of information simultaneously (e.g. Coreference, Syntactic Structure, Positional Relation, Semantic Focus)
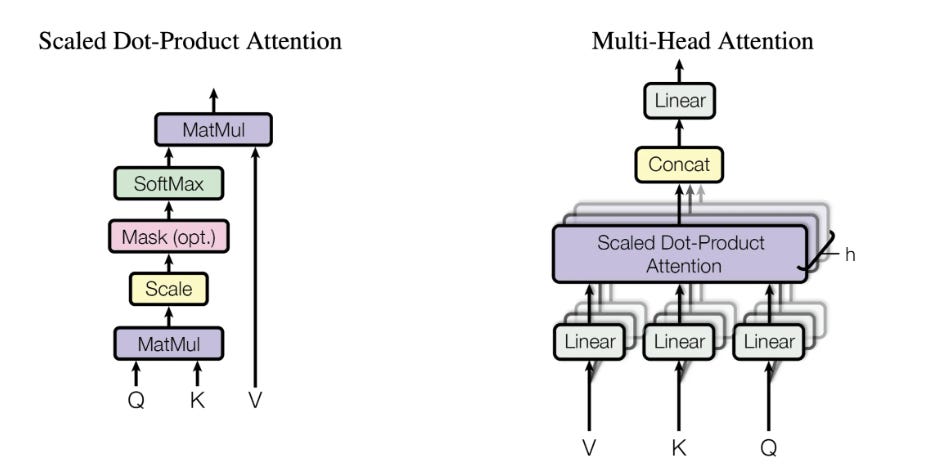
How Multi-Head Attention Works
Multi-head attention:
Splits the embedding dimension into multiple "heads"
Each head learns different attention patterns
Heads might focus on different aspects: syntax, semantics, long-range dependencies
Results are concatenated and projected back to the original dimension
Benefits of Multiple Heads
Different attention heads often specialize in different linguistic phenomena:
Head 1: Might focus on syntactic relationships (subject-verb agreement)
Head 2: Could attend to semantic relationships (word meanings)
Head 3: Might capture long-range dependencies (pronouns to antecedents)
This parallel processing allows the model to capture the rich, multi-faceted nature of language.
Sample Scenario: Sentence => "The cat sat on the mat because it was warm."
Head 1: Coreference: Learns that “it” refers to “the mat” (not the cat).
Head 2: Syntactic Structure: Understands that “the cat” is the subject of “sat.”
Head 3: Positional Relation: Notices “sat” happens before “because,” influencing causality.
Head 4: Semantic Focus: Pays attention to the meaning of "warm" and its relation to comfort.
Feed-Forward Networks
After the attention mechanism processes tokens, each position passes through a feed-forward network (FFN). This component:

Structure and Function
Consists of two linear transformations with a non-linear activation (typically ReLU or GELU)
Applies the same transformation to each position independently
Typically expands the dimensionality by 4x in the hidden layer, then projects back
FFN(x) = max(0, xW₁ + b₁)W₂ + b₂Purpose in the Architecture
The feed-forward network serves as a form of position-wise processing that:
Integrates information gathered by attention
Performs non-linear transformations
Acts as a "memory" storing factual knowledge
Enables complex pattern recognition
Decoder Block Layer Structure
Each transformer layer (whether encoder or decoder) typically contains:
Multi-head attention (with residual connections and layer normalization)
Feed-forward network (with residual connections and layer normalization)

3-Dimensionals LLM Architecture
Please take a look at this to see the complete LLM architecture:
LLM in 3D: https://bbycroft.net/llm
Typical Layer Counts
Different LLMs use varying numbers of layers:
GPT-3: 96 layers
GPT-4: Estimated 120+ layers
Claude: Specific architecture not disclosed, but likely 80-100+ layers
LLaMA-2 70B: 80 layers
Llama2-7B: 32 Layers, 32 Multi Head Attention
Why Deep Architectures?
More layers allow for:
Greater abstraction and complexity
Better capture of long-range dependencies
More sophisticated reasoning capabilities
Higher capacity for storing knowledge
Training Infrastructure: GPUs and Compute
GPU Requirements
Training large language models requires massive computational resources:
Example Training Setups
GPT-3 (175B parameters):
Hardware: NVIDIA V100 GPUs
Cluster size: Thousands of GPUs
Training time: Several weeks
Estimated cost: $4-12 million
GPT-4:
Hardware: Likely A100 or H100 GPUs
Cluster size: Estimated 10,000+ GPUs
Training time: Months
Estimated cost: $50-100 million
LLaMA-2 70B:
Hardware: A100 GPUs
Training time: 1.7 million GPU hours
Cluster size: 2,048 A100 GPUs for several months
Training Challenges
Training LLMs involves:
Memory Requirements: Models often exceed single GPU memory, requiring model parallelism
Communication Overhead: Distributed training requires efficient communication between GPUs
Numerical Stability: Training stability becomes challenging at scale
Data Pipeline: Feeding data efficiently to thousands of GPUs simultaneously
Learned Parameters in LLMs
At the core of every Large Language Model (LLM) lies billions of parameters that are learned during training. These parameters are not just abstract numbers; they encode the model’s entire knowledge about language, grammar, semantics, world facts, and reasoning. Understanding what these parameters are and where they reside within the model architecture (like embeddings, attention layers, and feedforward networks) helps to learn how LLMs work. Below is a breakdown of the key parameter categories learned during LLM training and their roles in transforming input tokens into intelligent outputs.
Token Embedding Matrix
Learns vector representations for input tokens (words/subwords).
Shape:
[vocab_size, embedding_dim]
Positional Embeddings
Learns how to encode position/order of tokens.
Shape:
[max_position, embedding_dim]
Attention Parameters
Each multi-head self-attention block learns:
Query weight matrix (Wq)
Key weight matrix (Wk)
Value weight matrix (Wv)
Output projection matrix (Wo)
For each head:
Shape:
[embedding_dim, head_dim]
Feedforward Network (FFN) Weights
In each transformer block:
First linear layer weights and biases
Shape:
[embedding_dim, ff_dim]
Second linear layer weights and biases
Shape:
[ff_dim, embedding_dim]
Layer Norm Parameters
Each normalization layer has:
Gain (gamma) and Bias (beta)
Shape:
[embedding_dim]
Final Layer (LM Head)
Maps hidden states back to vocabulary logits.
Often shares weights with token embedding matrix (weight tying).
Shape:
[embedding_dim, vocab_size]
Future Directions
As Large Language Models continue to evolve, researchers are prioritizing ways to make them faster, more cost-efficient, and more specialized. Innovations like mixture-of-experts and sparse attention reduce computational overhead while preserving performance. Simultaneously, new architectures are emerging for task-specific applications and multimodal understanding, integrating text with vision and audio. These trends are shaping a future where LLMs become increasingly efficient, accessible, and versatile across industries.
The field continues evolving with:
Efficiency Improvements: Techniques like mixture-of-experts and sparse attention
Specialized Architectures: Models optimized for specific tasks or domains
Multimodal Models: Integrating vision, audio, and text processing
Reduced Training Costs: More efficient training methods and hardware
Conclusion
LLMs represent one of the most significant advances in artificial intelligence, built on the foundation of transformer architecture with its attention mechanisms, embeddings, and deep neural networks. The combination of massive scale, sophisticated architecture, and enormous computational resources has enabled these models to achieve human-like performance on many language tasks.
Understanding how LLMs work, from the mathematical foundations of attention to the engineering challenges of training on thousands of GPUs, provides insight into both their current capabilities and future potential. As the field continues to evolve, we can expect even more powerful and efficient models that push the boundaries of what's possible with artificial intelligence.
The journey from simple word embeddings to models with trillions of parameters represents not just technological progress, but a fundamental shift in how we approach natural language understanding and generation. The transformer architecture and its innovations have created a new paradigm in AI that continues to surprise researchers and users alike with its emergent capabilities and potential.
Stay ahead of the AI and Cloud curve, in 5 minutes a week.
Every week, we scan through 30+ top sources, from cutting-edge GitHub projects to the latest arXiv research and key updates in AI & cloud infrastructure. You’ll get a concise, curated digest with no fluff, just actionable insights to keep you ahead of the curve.
Why subscribe?
🧠 Save time: We read the noise so you don’t have to.
📦 Get GitHub gold: Discover trending AI tools & repos.
📰 Understand breakthroughs: Sharp summaries of key arXiv papers.
☁️ Track infra evolution: Stay up-to-date on AWS, GCP, open source, and more.
📈 Boost your edge: Learn what top devs, researchers, and builders are using.
💡 1-2 email. Every week. No spam. Only value.
Ready to upgrade your signal-to-noise ratio? Subscribe now, it’s free.